


If a High-Profile U.S. Manufacturer Can Be Taken Down by DoppelPaymer, Everyone Is Vulnerable
Why this attack matters — and what engineering organizations must do now.
Last year's DoppelPaymer incident that knocked a well-known U.S. manufacturer offline should be a wake-up call for every engineering and manufacturing team in the country. This wasn’t some small office being inconvenienced — it was a supplier with complex CAD, PDM and ERP systems, and the attack exposed exactly how fragile modern engineering workflows are when the right protections aren’t in place.
The blunt truth: if a sophisticated operator can break into a high-profile manufacturer with mature IT, your organization is at risk too. Ransomware groups like DoppelPaymer aren’t random opportunists; they target high-value victims, steal intellectual property, and weaponize recovery gaps. You don’t have to be careless to be breached — you just have to be reachable.
Here’s what happened at a high level, why it matters for you, and the concrete steps every engineering organization should adopt immediately.
What made this attack so destructive
DoppelPaymer is a double-extortion operator. They don’t only encrypt systems — they quietly copy terabytes of sensitive data, then threaten to publish it if a ransom isn’t paid. For an engineering shop that means design models, bill-of-materials, manufacturing drawings, vendor contracts and financials suddenly sit on an attacker’s server.
Typical attack patterns include:
-
Credential theft and phishing to gain initial access
-
Abuse of exposed remote access (RDP, VPN appliances) or unpatched edge devices
-
Lateral movement to PDM/CAD servers and databases that hold the real crown jewels
-
Data exfiltration followed by wide encryption and public shaming to force payment
The outcome is predictably severe: design systems taken offline, production halted, partners and suppliers exposed, and long-term damage to trust and innovation pipelines.
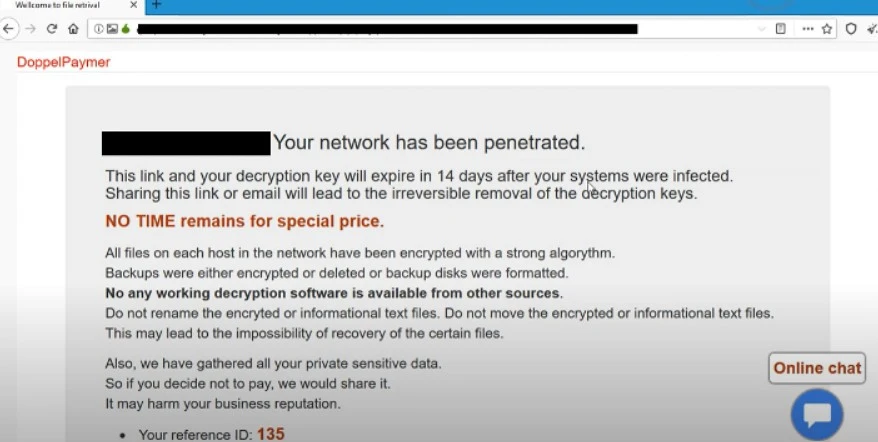
Why “we patch, so we’re safe” is not enough
Patching and updates are necessary, but they’re only one layer. The attackers in this case found ways to bypass those defenses — through identity compromise, exposed services, or misconfigured backups. A single missing control on a domain controller or an accessible file server can negate months of hardening.
Put another way: security isn’t a checklist you finish and forget. It’s the intersection of people, process and technology — and attackers exploit gaps in any of those three.
A pragmatic defense: prevention, detection, and recovery
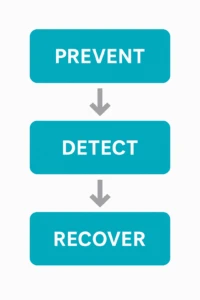
1) Prevent: reduce the attack surface
-
Harden remote access. Require MFA for VPNs and remote desktop access. Remove any direct RDP exposure to the internet.
-
Least privilege for identities. Limit admin accounts, use break-glass processes, and ensure service accounts have narrowly scoped rights.
-
Segment production networks. CAD/PDM systems and ERP should be isolated from general office networks and internet-facing systems.
-
Lock down backup credentials. Ensure backup systems and keys are not reachable from production hosts.
-
Patch and inventory edge devices. Appliances like VPNs and firewalls must be tracked and updated — and monitored for suspicious configuration changes.
2) Detect: catch intrusions early
-
Endpoint detection & response (EDR). Deploy EDR across servers and engineering workstations to surface unusual behavior.
-
Network telemetry and logging. Capture north-south and east-west traffic, DNS logs, and authentication attempts. Correlate anomalies with identity behavior.
-
Threat hunting. Regularly scan for indicators of compromise and signs of data staging or exfiltration.
-
Identity monitoring. Alert on impossible travel, brute-force attempts, and anomalous privilege escalations.
3) Recover: because prevention fails sometimes
This is where many organizations fail hardest: they assume backups exist and will work under stress. In a ransomware or site-loss event, your recovery posture — not your patch cadence — determines how quickly you can get back to business.
Critical recovery practices:
-
Immutable, off-site backups. Backups must be write-once, tamper-proof and stored outside the production domain.
-
Frequent, application-consistent backups. For ERP and PDM, hourly or near-continuous protection for key databases is often required.
-
Isolated backup credentials and key escrow. Ensure attacker compromise of a server doesn’t give instant access to your backup vault.
-
Fast cloud failover. Be able to spin up server images and VMs in a trusted cloud environment within hours, not weeks.
-
Regular, documented DR runbooks and tests. Periodic restoration exercises validate assumptions, identify missing pieces and shorten RTOs.
-
Workstation recovery plans. Engineers’ local models and caches matter. Capture workstation images for rapid restore so design work can resume.
Practical checklist: steps you can take this week

-
Run a scoped inventory: list PDM vaults, CAD file stores, ERP instances, DCs, and backup targets.
-
Confirm MFA is enforced on all remote access and admin accounts.
-
Verify backups are immutable, encrypted, and stored off-domain in an isolated repository.
-
Test a full restore of at least one critical system into a clean environment.
-
Implement or validate segmentation around CAD/PDM and ERP systems.
-
Schedule a tabletop incident response exercise that includes ransom, data leak, and supplier notification scenarios.
Final word: plan for the worst, design for resilience
The industry’s lesson from the DoppelPaymer hit is stark: sophisticated attackers will find a way, and a breach of a major manufacturer proves that maturity alone doesn’t equal safety. If they are vulnerable, everyone is vulnerable.
Make recovery the centerpiece of your strategy. Patch, monitor and harden — absolutely — but pair those actions with durable, tested backups, clear runbooks, and the ability to run critical engineering workloads from a secure, isolated cloud while you recover. That’s the difference between an incident and an existential crisis.
If you’d like, Converge can help you map your CAD/PDM and ERP environment into a hardened recovery plan and implement cloud-hosted backups and fast failover with EpiGrid infrastructure. Because the only acceptable answer to “what happens next?” is: “we know, and we can get you back online.”